1. RocketMQ 架构概览
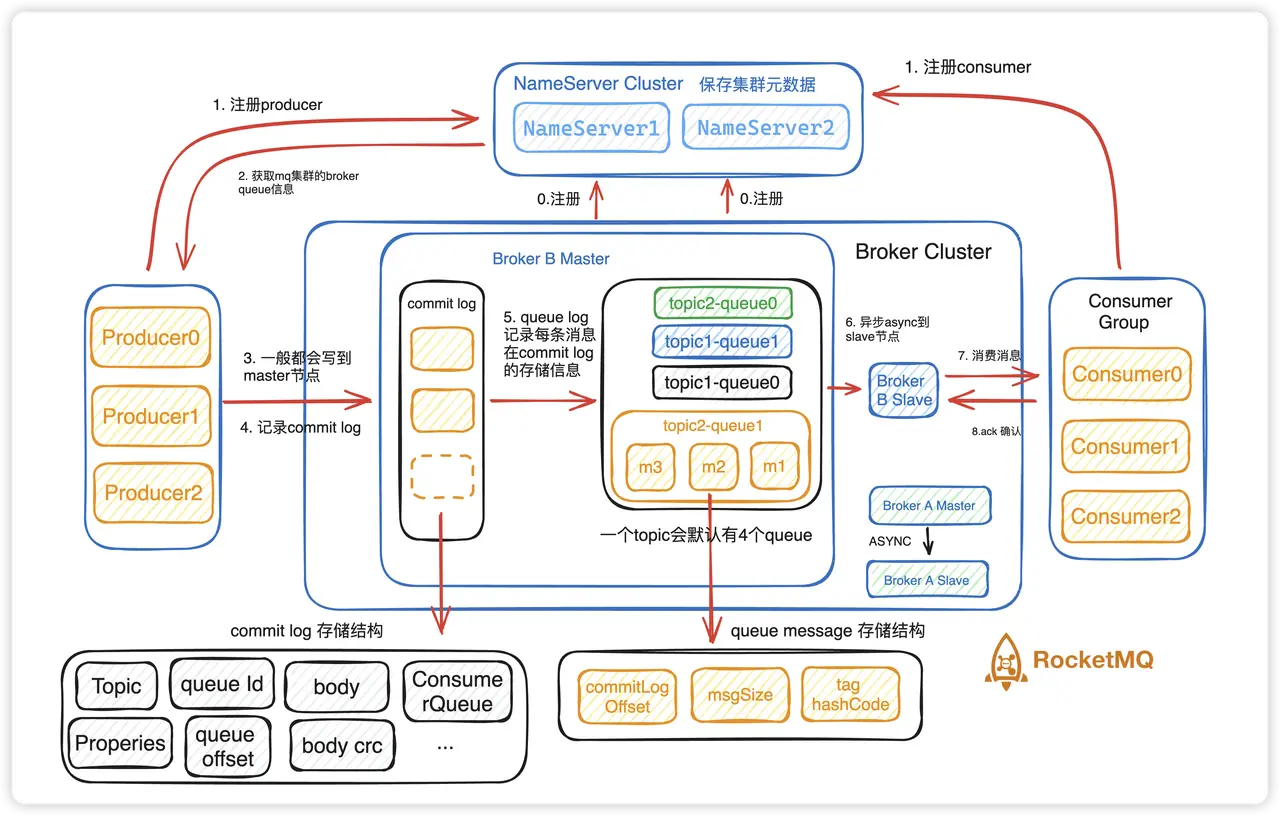
Producer(生产者):负责构造消息并发送到 Broker。
Broker(消息存储与转发):核心组件,负责:
接收消息写入存储(CommitLog)
构建消费索引(ConsumeQueue)
提供拉取/推送能力(客户端侧通常是“拉取 + 本地推送式消费”)
Consumer(消费者):从 Broker 拉取消息并执行业务逻辑。
NameServer:轻量注册中心,维护 Topic 路由信息(Broker 地址、队列信息等)。
2. Producer(生产者)
2.1 发送链路的核心理解
典型写入链路可以理解为:
Producer 发送消息到 Broker
Broker 写入 CommitLog(物理日志,顺序写)
Broker 构建/更新 ConsumeQueue(逻辑队列索引:指向 CommitLog 的偏移量等)
Broker 返回 ACK(或不返回,取决于发送模式/刷盘复制策略)
写入 commit log + 指针索引给到 queue”非常关键:
CommitLog:全局顺序写,追求吞吐
ConsumeQueue:面向消费检索(topic + queue)快速定位消息
2.2 同步消息(Sync / 串行)
流程(概念) Producer 发送 → Broker(可能涉及主从复制/刷盘策略)→ 返回 ACK → 业务代码继续执行
理解
优点:可靠性更好
缺点:慢;如果不返回 ACK,会阻塞发送线程
机制
发送线程阻塞,等待 Broker 响应(ACK)
失败表现
发送失败(如超时、无可用 Broker、磁盘满等)会抛异常:
RemotingException/MQClientException/MQBrokerException(常见)
默认策略(重要)
业务层面:不自动重试(不会替你写 try-catch 重试逻辑)
客户端内部:存在节点切换与一定次数的发送重试(见 2.7 自动容错机制)
开发者责任
必须 try-catch 捕获异常,并决定:
本地重试(谨慎:避免阻塞主线程、避免无限重试)
记录日志 + 走补偿
降级/兜底
2.3 异步消息(Async / 并行)
流程(概念) Producer 发送 → Broker 存储 → 异步回调通知 ACK 同时业务代码不阻塞,可继续执行。
理解
优点:快、吞吐高、调用线程不阻塞
缺点:可靠性取决于你如何处理回调失败;“代码先往下走”意味着业务更容易漏掉异常处理
机制
发送线程不阻塞,通过
SendCallback回调拿结果
失败表现
回调
onException(Throwable e)被触发
默认策略
同步/异步都一样:业务逻辑不自动重试,只是通知你失败了
开发者责任(推荐实践)
在
onException中实现重试与兜底:失败消息进入本地内存队列(仅适合短期,应用重启会丢)
更推荐:持久化(DB/本地消息表/可靠存储)+ 后台线程指数退避重试
2.4 单向消息(Oneway / 类 UDP)
流程(概念) Producer 发送 → 业务代码继续运行 不等待 ACK,也不关心成功与否。
理解
优点:性能最高、延迟最低
缺点:极不可靠(发送失败你也不知道)
失败表现
没有反馈:即使网络断了、Broker 不可用,也不会抛异常/回调通知
适用场景
日志收集
非关键监控数据
非核心指令(例如“写日志到磁盘”的触发指令等)
禁止场景
订单、支付、库存等核心链路
2.5 延迟消息(Delay)
流程(概念) Producer 发送 → 消息在 Broker 等待(延迟级别/时间)→ 时间到后消费者可见并消费
理解与场景
下单后未支付超时取消
定时任务/延迟触发
“最终一致性”的补偿触发(例如 X 分钟后校验状态)
适当拓展: 延迟消息在 RocketMQ 常见实现是“延迟级别”,不同版本/配置支持的延迟精度不同;需要结合你们版本确认是固定等级还是支持任意时间。
2.6 批量消息(Batch)
流程(概念) Producer 一次发送多条消息集合 → 打包发送到同一 Broker / 同一 Topic / 同一 Queue
理解
合理的批量可以减少网络 IO 与 RPC 次数,提高吞吐
注意:批量消息通常要求同 topic、同 queue 策略一致,且单次包大小受限制(例如 4MB 限制常见)
2.7 顺序消息(Orderly / 局部有序)
RocketMQ 顺序消息通常只能保证局部有序:
同一 Topic 默认多个队列(如 4 条队列)
通过
producer.send(msg, MessageQueueSelector, arg)常见策略:
hash(key) % queueNum保证同一业务 key 的消息进入同一队列,从而在队列内保持顺序
关键理解
“顺序消息”本质是在队列粒度保证生产顺序一致,但消费端如果并发消费仍可能乱序(见 3.1)
2.8 RocketMQ 客户端的自动容错机制
虽然代码层面需要自己写重试,但 RocketMQ 客户端底层有重要的自动容错:
场景:发送指定 Master,但该节点宕机/网络不通
行为:客户端会检测异常,并尝试发送到该 Topic 的其它可用 Broker 节点(通常是同组其他 Master)
配置:受
retryTimesWhenSendFailed(同步)/retryTimesWhenSendAsyncFailed(异步)等参数影响(默认通常会尝试若干次,比如 2 次)局限:如果整个集群不可用,最终仍会失败并抛异常/回调异常
注意:这类“内部重试/切换”并不等同于你业务上的“保证最终投递成功”。 业务想要“最终一致性”,仍要靠补偿架构(见 2.9)。
2.9 消息发送失败/丢失的补偿策略(高可靠架构)
生产环境中只在 try-catch 里 Thread.sleep 重试是不够的,因为应用重启后内存重试任务会丢失。
推荐方案:本地消息表(Local Message Table)+ 定时补偿
这是保证消息最终一致性的常见“黄金标准”(尤其金融/核心业务)。
(1) 本地事务:业务数据与消息记录同事务落库
在业务数据库创建
message_log表在执行核心业务(如扣减库存)的同一个本地事务中:
写入业务数据
插入消息记录,状态为
SENDING
提交事务
业务数据与消息要么同时成功,要么同时失败
(2) 发送消息:事务提交后投递 MQ
提交后调用
producer.send()成功:更新
message_log状态为SENT失败:保持
SENDING,记录异常信息
(3) 定时补偿(关键)
后台定时任务(例如每 5 秒扫描一次)
查询
SENDING且创建时间超过阈值(避免并发竞争)重发消息
成功:更新为
SENT超过最大次数(如 10 次):标记
FAILED,报警 + 人工处理
优点
不丢消息:只要 DB 不挂,消息记录就在;应用重启仍可继续补偿
解耦:主业务流程不需要陷入复杂重试等待
死信队列(DLQ)作为最后兜底
开启/关注死信队列
人工排查、回放或修复数据
3. Consumer(消费者)
3.1 消费监听器:并发 vs 顺序
3.1.1 并发消费(默认)
consumer.registerMessageListener(new MessageListenerConcurrently(){...})默认并发模式:每个 consumer 通常有 20 个线程(常见默认值)
对一个 topic(或 topic+tag)消费时,会对队列(默认如 4 条)进行轮询消费,类似 CPU 时间片轮转,提高吞吐
3.1.2 顺序消费
consumer.registerMessageListener(new MessageListenerOrderly(){...})疑问: Producer 已经把同一业务 key 的消息放进同一队列了,那 consumer 并发模式不是也能读到顺序吗?顺序模式还有什么意义?
核心答案
顺序消息只能保证进入同一队列从而保证“队列内的存储顺序”。
但并发消费下,同一队列的多条消息可能被多个线程同时处理,导致完成顺序不同,从而业务表现乱序:
例如队列顺序 a、b、c、d
并发执行耗时不同,可能变成 c 先完成,然后 b、d、a ……
结果:业务侧还是乱序
RocketMQ 顺序消费的机制
RocketMQ 的顺序消费基于 MessageQueue(队列)粒度的锁,不是 consumer 实例的全局锁
即使配置有 20 个线程:
同一时刻每个队列最多由 1 个线程串行消费
因此并发上限 ≈ 队列数
示例:Topic 有 4 个队列
Queue0 被线程 A 锁定并串行处理
Queue1 被线程 B 锁定并串行处理
Queue2 被线程 C 锁定并串行处理
Queue3 被线程 D 锁定并串行处理 其余线程空闲等待
关键点
Queue0 的慢不会影响 Queue1/2/3
但 Queue0 内部一定是串行执行,保证顺序
3.2 消费失败后的策略:重试与死信队列
并发模式
默认重试 16 次
仍失败 → 进入死信队列(DLQ)
顺序模式
无限重试(
Integer.MAX_VALUE)
总体流程
消费失败 → 自动重试(普通消息默认 16 次,顺序消息无限次) → 死信队列(DLQ) → 人工处理 / 也可自定义 consumer 定时消费 DLQ(例如 Topic:%DLQ%retry-consumer-group) → 最终报警(邮件/告警平台)给运维/值班
4. Topic 与 Tag:为什么需要 Tag?
Topic:对一大类消息的划分(如
Order-Topic)Tag:对 Topic 下更细粒度的子分类
例 carOrder、houseOrder 本质都是 order
如果每个子业务都拆成一个 Topic 会冗余、管理成本高
因此用 Tag 在同一 Topic 下再细分
补充:Tag 也常用于消费端的过滤与路由,但要注意不要把 Tag 当成“无限维度的字段过滤”,复杂条件更适合用 Properties + SQL92 过滤(见 6.3)。
5. 消费模型与消息生命周期
5.1 消费关系:Group 之间广播、Group 内竞争
同一 Topic 被不同订阅它的消费者组(Consumer Group)消费时:
组与组之间:广播关系(每个 Group 都会消费到同一条消息)
组内多个 Consumer 实例:竞争关系(同一条消息只会被组内一个实例消费)
5.2 消息被消费完会消失吗?
不会。消息有自己的生命周期与清理策略:
若设置 TTL,则按 TTL 过期
若未设置 TTL,则常见默认保留时间为 72h(以实际配置为准)
磁盘写满 → 触发过期删除/拒绝写入等策略(见 9)
消费完成后,Group 只是在维护一个 offset(消费进度):
Broker 端消息仍保留在 CommitLog / ConsumeQueue 中
offset 类似“书签”,指向下一个待消费消息
原消息不会因为“被消费”就立刻删除
5.3 同一消费者组内的消费模式
负载均衡(默认)
一条消息只会投递给该 group 中的一个 consumer
组内共享 offset
广播
一条消息会投递给同 group 的所有 consumer
每个 consumer 有自己的 offset
应用场景:
本地缓存同步(如每台机器刷新 Caffeine)
本地日志/埋点上报
配置热更新
WARNING:广播没有重试机制!
5.4 消费者组如何划分(重要约束)
同一消费者组(同一 group)通常必须满足:
group 名称相同
订阅范围必须完全一致
如订阅
*(所有 Tags)或订阅某 Tag
或
Tag1 || Tag2如果订阅范围不同,可能导致:消息紊乱
消息丢失
重复消费
6. 消息结构:Message / MessageExt
RocketMQ 的消息结构不仅是“头 + 体”,更明确可分为三部分:
Message Header(消息头):系统级元数据(路由、存储、基础控制)
Message Body(消息体):业务数据(byte[])
Message Properties(消息属性):扩展元数据(系统内置 + 用户自定义)
代码层面:
Producer 发送:
MessageConsumer 接收:
MessageExt(扩展了存储侧元数据)
6.1 Message Header(消息头)
特点:字段相对固定,由 RocketMQ 自动维护;用户通常不直接改大多数头字段(或不需要改)。
常见字段:
topic:主题(决定路由)⭐⭐⭐⭐⭐tags:标签(用于二级过滤)keys:业务键(如订单号),便于查询轨迹 ⭐⭐⭐⭐flag:生产者设置标记位,框架不处理 ⭐⭐waitStoreMsgOK:是否等待存储确认(刷盘/复制相关)⭐⭐transactionId:事务消息 ID ⭐⭐⭐(事务场景)
注:某些版本实现上 topic/tags/keys 可能落在 properties 中存储,但 SDK 逻辑上把它们视作标准头字段。
6.2 Message Body(消息体)
类型:
byte[]内容:JSON、Protobuf、图片流、或任意序列化数据
限制:默认最大 4MB(可调但不建议过大,会影响吞吐与内存)
示例:
String body = "OrderID:1001,Action:PAY";
message.setBody(body.getBytes(RemotingHelper.DEFAULT_CHARSET));6.3 Message Properties(消息属性)
特点:Map<String, String>,最灵活的扩展点。
A. 系统内置属性(示例)
UNIQ_KEY:消息全局唯一 ID(系统自动生成)TAGS:对应 tagsKEYS:对应 keysWAIT_STORE_MSG_OK:是否等待存储成功TRAN_MSG:是否事务消息PGROUP:生产者组DELAY_TIME_LEVEL:延迟级别RETRY_TOPIC:重试目标 TopicMAX_RECONSUME_TIMES:最大重试次数
B. 用户自定义属性(支持 SQL92 过滤)
message.putUserProperty("orderId", "1001");
message.putUserProperty("userLevel", "VIP");
message.putUserProperty("region", "CN-HANGZHOU");消费端过滤示例:
consumer.subscribe("TopicTest", "userLevel == 'VIP' && region == 'CN-HANGZHOU'");6.4 Consumer 视角:MessageExt 增强字段
MessageExt 增加 Broker 存储相关元数据(发送时不存在,存储后生成):
msgId:Broker 全局唯一存储 ID(不同于 UNIQ_KEY)→ 精确查询/去重queueOffset:在 ConsumeQueue 的逻辑偏移 → 记录消费进度storeTimestamp:存入 Broker 时间 → 计算堆积时长bornTimestamp:消息创建时间 → 计算链路耗时storeHost/bornHost:存储/发送地址 → 追踪来源reconsumeTimes:重试次数 → 判断是否重试消息commitLogOffset:在 CommitLog 的物理偏移 → 底层定位
6.5 示例:查看完整结构
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
// 1. 获取消息体 (需要自己反序列化)
String body = new String(msg.getBody(), RemotingHelper.DEFAULT_CHARSET);
// 2. 获取标准头信息
String topic = msg.getTopic();
String tags = msg.getTags();
String keys = msg.getKeys();
// 3. 获取所有属性 (包含系统属性和自定义属性)
Map<String, String> props = msg.getProperties();
String uniqKey = props.get(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);
String myBizField = props.get("myCustomField");
// 4. 获取存储元数据 (MessageExt 特有)
long offset = msg.getQueueOffset();
Date storeTime = new Date(msg.getStoreTimestamp());
int retryTimes = msg.getReconsumeTimes();
System.out.println("收到消息: " + body);
System.out.println("唯一ID: " + uniqKey + ", 重试次数: " + retryTimes);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});实践建议 即使有 msgId / UNIQ_KEY,也建议业务自己生成唯一业务 key(如雪花、UUID、业务名+机房+IP+时间等),用于:
业务追踪与排查
幂等去重
对账与回放
7. 消息重复消费问题(幂等性)
7.1 为什么会出现重复消费?
生产者多次投递
MQ 网络延迟/抖动
Producer 未收到 ACK 误以为失败而重试
导致重复发送
消费者组扩容导致 Rebalance 重复消费
例如 group 中原有 3 个 consumer 消费 4 个队列(1、1、2 分配)
新增一个 consumer → 触发 rebalance → 变为 1、1、1、1
因为消费过程不是原子:
先执行业务,再提交 offset(或相反,具体实现/调用点导致风险)
若“业务已完成但 offset 未提交”就发生 rebalance,新的 consumer 可能继续从旧 offset 拉取,造成重复消费
7.2 如何解决重复消费(核心:幂等)
使用唯一标识(
msgId/keys/ 自定义业务 key)做去重推荐把去重 key 落到 MySQL(更稳),Redis 也可但要考虑:
内存成本
Redis 故障导致去重信息丢失
推荐流程
准备去重表(例如
msg_dedup),把 key 设为UNIQUE消费前先尝试
INSERT key插入成功:说明首次消费 → 执行业务逻辑
插入失败(唯一键冲突):说明重复 → 直接 ACK/跳过
若业务执行失败:
回滚业务
删除去重表对应 key(避免“失败但被认为已消费”)
适当拓展: 在高并发下注意“先去重再执行业务”的事务边界设计,避免出现“去重成功但业务失败”的不一致窗口(你已写到失败要 delete,方向正确)。
8. 消息堆积(积压)
8.1 什么是消息堆积?
Broker 队列中未被消费的消息大量堆积:
生产速度 V(produce) >>> 消费速度 V(consume)
单队列 offset 积压达到很大数量(例如 >= 10w)
8.2 为什么会出现堆积?
消费者实例太少 / 线程池小 / 接口耗时长(慢查询)
消费阻塞:死循环、死锁、数据库连接池耗尽等待
流量突增
硬件/网络问题
队列分配不均(消费热点)
8.3 怎么解决?
增加消费者实例、增加 Topic 队列数
消费者数量 <= 队列数量,多了也没用(抢不到队列)
调大消费线程数(线程池调整)
RocketMQ 的消费线程数基本对应业务并发度
想快就调大,想稳就调小
不要随意再套一层“自建异步线程池”把问题复杂化(除非数据库连接池等确实需要隔离)
跳过非核心消息(如日志类)或降级处理
优化 SQL、减少 IO 耗时
Producer 限流(从源头削峰)
9. 如何确保消息不丢失?
9.1 消息丢失的常见原因
RocketMQ 理论上可做到非常高可靠;真丢多半是业务代码/配置问题
发送失败无兜底:异常不处理
使用单向发送(oneway)
Broker 默认异步刷盘:写入内存 Buffer/PageCache 后未落盘即宕机
主从同步时丢失:主写入内存但未完成同步复制,主挂导致丢
消息堆积导致过期(默认 72h)
磁盘写满(例如达到 85%)拒绝写入
9.2 解决方案(按可靠性增强链路)
核心业务开启同步刷盘
只有真正写入磁盘才返回 ACK(更慢但更稳)
主从复制开启同步双写/同步复制
主必须等待从同步完成才返回 ACK(主线程会阻塞)
核心业务消息 TTL 设置更长(或调整保留策略)
运维与监控:
实时监控磁盘水位、写入失败、堆积量、DLQ
定期备份与演练
9.3 “Broker 明明有消息,但消费者消费丢了”常见原因
业务代码漏洞:先提交 offset,后执行业务,业务出错 offset 无法回滚
异常被吞:catch 了但手动返回成功 ACK
广播模式容易丢(且无重试机制)
不处理死信队列,不做兜底补偿
10. 最小落地清单(把关键点变成检查项)
这一节是“适当拓展”:不减少原内容的前提下,把笔记里的关键实践收敛成可执行检查项。
核心链路禁止 oneway
Producer 发送失败必须有兜底(本地消息表/补偿任务)
Consumer 必须幂等(去重表/唯一业务 key)
顺序业务必须使用
MessageListenerOrderly(且队列选择策略固定)DLQ 必须有监控 + 人工/自动处理流程
堆积监控(topic、group、queue 维度)与扩容预案
磁盘水位监控(写满拒写是灾难性问题)
广播模式只用于允许丢的场景(“无重试”)


